
The Autopsy of a 50% Gross Margin: Operational Discipline over Heroics

In the technology services industry—whether running a digital agency, a consultancy, or an internal engineering cost center—there is a pervasive myth: "If we just sell more, we’ll be profitable."
This is the "Revenue Trap." It assumes that profitability is a linear function of volume. The logic suggests that if the margin is thin at $5M revenue, surely it will fatten up at $10M via economies of scale.
It rarely does. Scaling a broken process just scales the losses.
In a previous operational turnaround for a 70-person technology organization, the team was incredibly busy. Everyone was working late. The sales pipeline was healthy. Yet, the Gross Margin (GM) was stuck at 39%.
We didn't need more sales. We needed operational physics. By applying rigorous resource allocation principles grounded in Queueing Theory, the organization moved the GM from 39% to 50% in under 18 months.
However, the journey was not a straight line. Applying rigid mathematical models to messy human systems creates new, unexpected dangers. Here is the autopsy of that turnaround—the theory, the execution, and the brutal reality checks required to make it stick.
1. The Diagnosis: The Map is Not the Territory
When we audited the workflows, we found a classic symptom of organizational chaos: High Utilization, Low Throughput.
The developers were 100% "booked" on the resource heatmaps. On paper, they had no free time. In reality, they were context-switching between 3-4 projects a day.
This highlights a critical philosophical distinction noted by Alfred Korzybski: The map is not the territory. The resource schedule (the map) showed a perfectly utilized machine. The actual daily experience of the engineer (the territory) was fragmented chaos.
The Data: The Context Switching Tax
The root cause was cognitive load. According to Gerald Weinberg’s research in Quality Software Management, every time a knowledge worker adds a concurrent project, they lose significant capacity to "switching costs."[^1]
Table 1: The Context Switching Tax
| Concurrent Projects | Time Spent on Value | Time Lost to Context Switching |
| 1 Project | 100% | 0% |
| 2 Projects | 80% | 20% |
| 3 Projects | 60% | 40% |
| 4 Projects | 40% | 60% |
| 5 Projects | 20% | 80% |
Our audit revealed our developers were averaging 3.5 concurrent projects. That meant nearly 50% of our payroll expense was being burned on "switching mental gears," not writing code.

2. The Cure: Via Negativa (Improvement by Subtraction)
To fix this, we had to embrace the concept of Via Negativa—a principle often cited by Nassim Taleb. We did not solve the problem by adding more coordinators, more software, or more managers. We solved it by subtracting the interruptions.
We moved from ad-hoc resource assignment ("Who is free today?") to a strict Resource Booking System. This wasn't just a process change; it was a philosophical shift from "optimizing for busyness" to "optimizing for flow."
A. The "Hard Booking" Rule
We stopped assigning people to tasks; we assigned them to outcomes for fixed blocks of time.
- The Rule: A developer is booked for a sprint (1-2 weeks). During that time, they are invisible to other projects.
- The Result: Context switching dropped to near zero. Deep work increased.
B. The Critical Split: "Run" vs. "Build"
The biggest killer of margin is the "interrupt." A developer focused on a high-value architecture build gets pinged to fix a CSS bug on a legacy site.
To solve this, we separated engineering talent into two distinct units:
- The Project Team (Build): Focuses on new revenue. Zero interruptions allowed.
- The Maintenance Team (Run): Focuses on tickets and SLAs. Structured specifically to absorb the noise.
The Reality Check: The "Caste System" Risk
While this model is mathematically sound, it introduces a severe human risk. If you permanently assign people to the "Run" team, you create a two-tier class system. The "Build" team gets the glory and the resume-building tech; the "Run" team gets the drudgery.
The Consequence: If you ignore this, your "Run" engineers will quit every 6 months. Your recruitment costs will skyrocket, destroying the margin gains you just made.
The Mitigation: The "Tour of Duty"
We implemented a rotation policy. No one stays in "Run" forever. It is a "Tour of Duty" (e.g., 3 months) that rotates. Furthermore, we gamified the Run team: their job wasn't just to fix bugs, but to write the automation that prevented the bugs. This turned a "janitorial" role into a DevOps engineering challenge.
3. The Financial Impact (The P&L View)
The math of efficiency is brutal. When you stop paying for context switching, that money goes straight to the bottom line. We achieved a 50% Gross Margin.
Table 2: The P&L Impact
| Metric | Before (Chaos) | After (Discipline) | Variance |
| Revenue | $1,000,000 | $1,000,000 | - |
| Cost of Delivery (COGS) | $610,000 | $500,000 | -$110,000 |
| Gross Margin ($) | $390,000 | $500,000 | +$110,000 |
| Gross Margin (%) | 39% | 50% | +11 pts |
The "Sellable Capacity" Fallacy
A warning to the Finance department: Efficiency does not equal Revenue; it only equals Potential Revenue.
In a factory, if you make widgets faster, you put them in inventory. In services, time is a perishable asset. We freed up 28% of our engineering capacity. However, if Sales had not filled that specific slot immediately, our P&L would have remained flat (we still pay the salaries).
The Fix: Operational discipline must be synced with Sales velocity. We had to build a "Capacity Forecast" mechanism so Sales knew exactly what inventory was becoming available 60 days out.
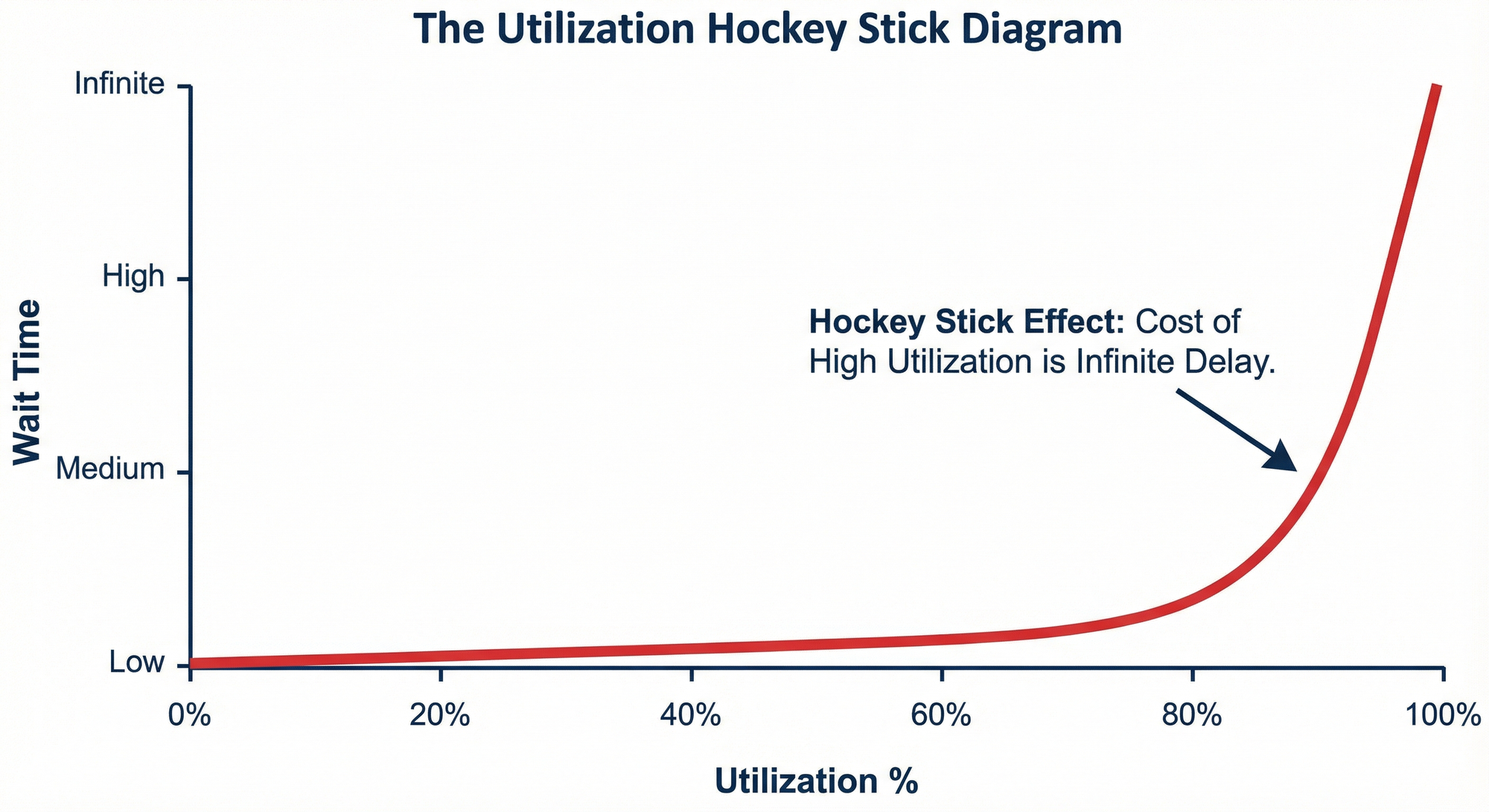
4. The Physics of the Queue
Why do leaders resist this? Because 100% utilization feels safe. Seeing an employee "not busy" triggers executive anxiety.
But in systems thinking, a system running at 100% utilization has 0% capacity for change and infinite wait times. This is defined by Little's Law:[^2]
L = λW
(Where L is the number of items in the system, λ is the arrival rate, and W is the wait time).
If your team is 100% utilized, any new request (a bug, a client change, a server crash) creates an exponential delay in the queue.
The Rigidity Risk: The "Red Phone" Protocol
The downside of "Hard Booking" is that it makes the organization rigid. If a top-tier client has a genuine emergency and we say, "Sorry, wait two weeks," we lose the account.
The Mitigation: We installed a metaphorical "Red Phone."
We allowed for emergency interruptions, but we added friction. Breaking a "Build" sprint required C-level sign-off. This ensured that true emergencies were handled, but "fake urgency" was filtered out.
Summary & Next Steps
Profit isn't found in the sales pipeline. It's found in the queue. To replicate this 50% Gross Margin model, execute the following:
- Audit WIP: How many projects is each developer touching per week? If it's >2, you are bleeding money.
- Isolate the Noise: Create a dedicated "Run" team, but rotate staff through it to prevent burnout.
- Hard Booking: Implement a policy where "Build" resources cannot be borrowed for ad-hoc tasks without C-level override.
- Sync with Sales: Ensure the capacity you free up is immediately sold.
References & Notes
[^1]: Weinberg, Gerald M. Quality Software Management: Vol. 1 Systems Thinking. Dorset House, 1992. (See Chapter 12 on the cost of context switching).
[^2]: Little, John D. C. "A Proof for the Queuing Formula: L = λW". Operations Research, 1961.
[^3]: Modig, Niklas & Åhlström, Pär. This is Lean: Resolving the Efficiency Paradox. Rheologica Publishing, 2012.
No spam, no sharing to third party. Only you and me.




Member discussion