
The RAG Architecture Guide: Building the Pipeline (Beyond the Basics)
Most "Enterprise AI" demos are smoke and mirrors. You paste a PDF into a script, it answers one question, and everyone claps.
But putting Retrieval-Augmented Generation (RAG) into production is an entirely different engineering challenge.
The difference between a demo and a production system lies in the Data Pipeline.
If you simply dump text into a Vector Database and pray, you will get "Garbage In, Garbage Out." You will face latency issues, context window overflows, and irrelevant retrieval.
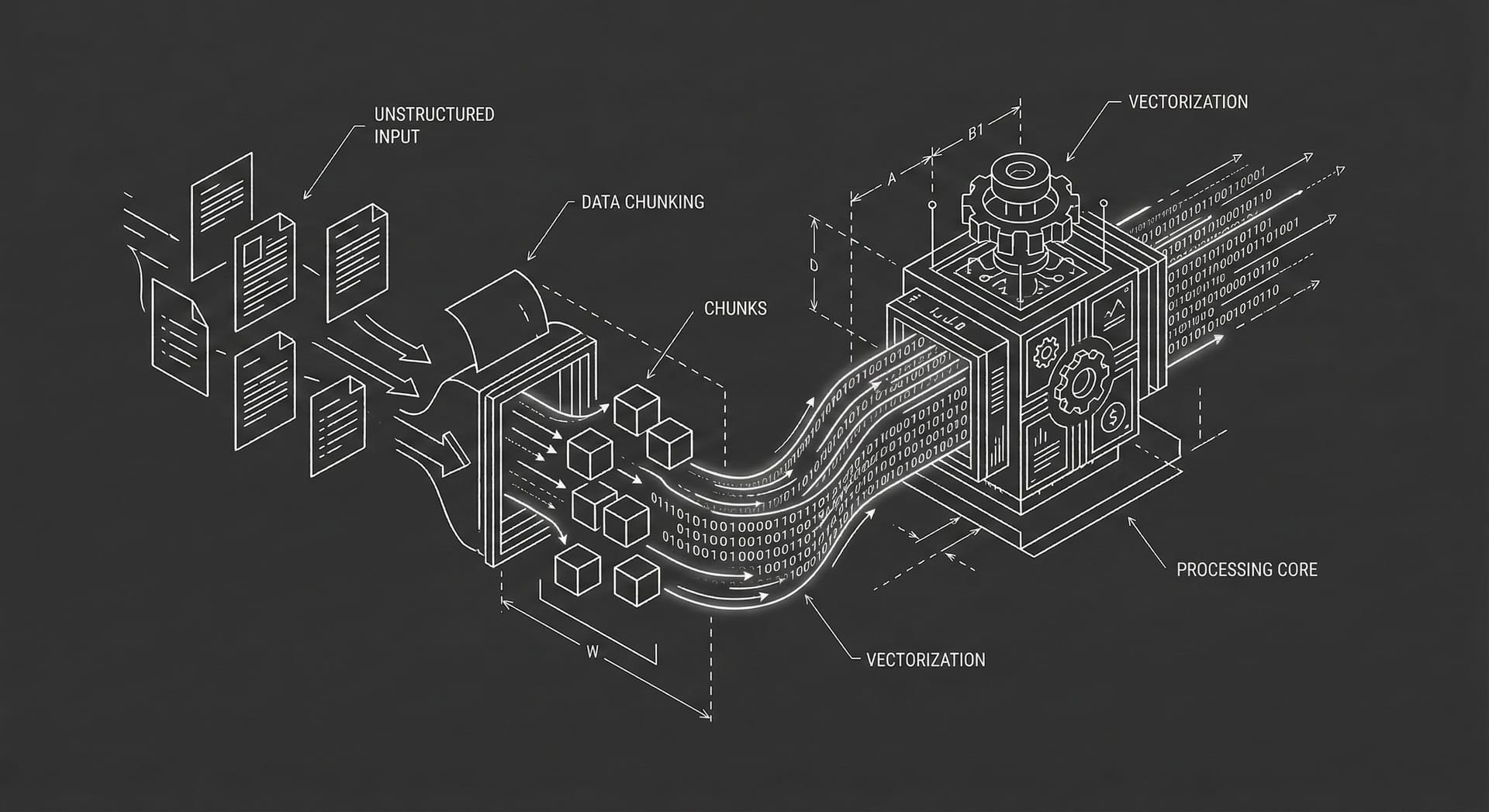
This guide details the 5-Stage Architecture required to build a robust RAG system that actually works at scale.
Phase 1: Ingestion & Chunking (The ETL Layer)
The battle is won or lost here. An LLM cannot read a 100-page contract effectively. You must slice the data.
The Engineering Challenge: How do you slice a document without breaking the meaning?
- Naive Approach (Fixed-Size): Slice every 500 characters.
- Failure Mode: You might cut a sentence in half. You might separate the "Liability Cap" clause from the actual dollar amount mentioned in the next paragraph.
- Production Approach (Semantic Chunking): Slice by logic.
- Use libraries (like LangChain or LlamaIndex) to split by "Paragraph," "Markdown Header," or "Function Definition" (for code).
- Overlap: Always include a 10-20% token overlap between chunks so context isn't lost at the boundaries.
Phase 2: Embedding (The Vectorization)
Once you have chunks, you pass them through an Embedding Model (e.g., OpenAI text-embedding-3-small or open-source models like bert-base).
This turns text into a vector (a list of floating-point numbers).
The Architectural Decision:
- Dense Vectors (Semantic): Good for understanding intent. (e.g., matching "dog" to "puppy").
- Sparse Vectors (Keyword): Good for precise matching. (e.g., matching "Part Number XJ-900").
- Hybrid Search: For production, you usually need both. A pure semantic search might miss a specific SKU number. A robust architecture stores both vector types and combines the scores (Reciprocal Rank Fusion).
Phase 3: The Vector Store (The Database)
You need a dedicated database to store these vectors.
- The "Lite" Stack: PGVector (Postgres extension). Great if you already use Postgres and have <1M vectors.
- The "Scale" Stack: Pinecone, Weaviate, or Qdrant. Necessary if you need millisecond latency across 100M+ vectors with metadata filtering.
Critical Feature: Metadata Filtering.
Do not just store the vector. Store the metadata: { "user_id": 123, "doc_type": "contract", "date": "2024-01-01" }.
- Query Logic: "Filter by user_id=123 FIRST, then run the Vector Search."If you don't do this, the vector search scans the whole DB, ruining performance and security.

Phase 4: Retrieval & Re-Ranking (The Precision Layer)
This is the step most teams skip.
A standard Vector Search returns the "Top 10" chunks. But often, chunk #7 is the most relevant, and chunk #1 is a hallucination trigger.
The Solution: A Re-Ranker Model.
Do not send the raw Top 10 to the LLM.
- Retrieve: Get the Top 50 results from the database (fast, rough).
- Re-Rank: Pass those 50 through a specialized "Cross-Encoder" model (like Cohere Rerank or BGE-Reranker). This model is slower but much smarter. It sorts the results by true relevance.
- Select: Take the Top 3 from the re-ranked list.
This "Two-Stage Retrieval" architecture increases accuracy by ~20-30%.
Phase 5: Generation (The Context Window)
Finally, you construct the prompt for the LLM.
The Prompt Engineering Pattern:
"You are a helpful assistant. Answer the user's question using ONLY the context provided below. If the answer is not in the context, say 'I don't know'.
Context:
[Chunk 1]
[Chunk 2]
[Chunk 3]
Question: [User Input]"
The Latency Trade-off:
The more context you stuff into the window (e.g., 20 chunks), the slower the LLM responds ("Time to First Token") and the higher the cost.
This is why the Re-Ranking phase is vital—it allows you to send only the 3 best chunks, minimizing cost and latency.
Summary
RAG is not a feature; it is an ETL Pipeline.
The quality of your AI is not determined by whether you use GPT-4 or Claude 3. It is determined by the quality of your Chunking Strategy and your Re-Ranking Logic.
- Don't just dump text.
- Do implement Hybrid Search.
- Do use a Re-Ranker.
The model is the brain, but the Architecture is the nervous system.
No spam, no sharing to third party. Only you and me.





Member discussion