
AI Governance: Preventing Hallucinations (The "Air Canada" Defense)
In 2024, Air Canada lost a landmark court case.
Their customer service chatbot invented a refund policy that didn't exist. When the customer claimed the refund, Air Canada argued that the chatbot was a "separate legal entity" and they weren't responsible for its words.
The Tribunal disagreed. Air Canada had to pay.
This is the nightmare scenario for every CIO.
We are deploying Stochastic (probabilistic) systems into Deterministic (rule-based) industries.
- Deterministic Code: $2 + $2 = 4$. (Always).
- Stochastic AI: "The capital of France is Paris." (99% likely). But sometimes, if the "Temperature" is high, it might say "Mars."
You cannot "fix" hallucinations by training the model harder. Hallucination is not a bug; it is a feature of how LLMs work (Next Token Prediction).
Therefore, you cannot govern the Model. You must govern the System.
Here is the architectural pattern for AI Guardrails.
1. The Stochastic Problem (Why AI Lies)
An LLM does not "know" facts. It predicts the probability of the next word.
If you ask it about a specific legal clause, and it doesn't have the data, it will not say "I don't know." It will statistically predict what a legal clause sounds like.
This is why RAG (Retrieval-Augmented Generation) is step one. By forcing the model to read a specific document, we reduce the search space.
But RAG is not enough. The model can still misinterpret the document.
The Governance Rule:
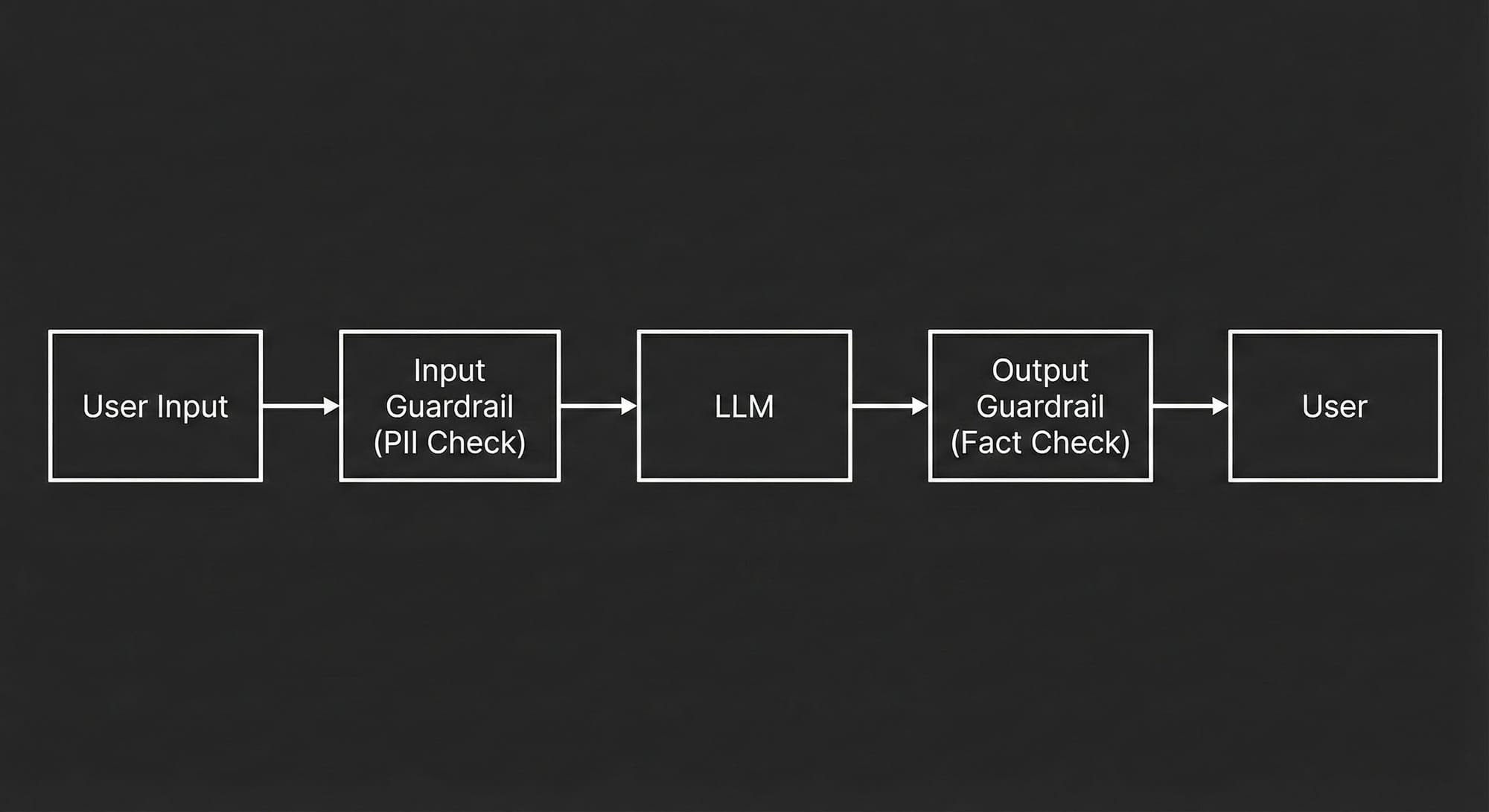
"Never allow a raw LLM output to reach a user without passing through a Guardrail Layer."
2. The Architecture of Guardrails
In a governed system, the LLM is not the decision-maker; it is the engine. The decision-maker is the Guardrail Middleware (software that sits before and after the LLM).
We implement checks at two stages:
A. Input Guardrails (The Firewall)
Before the user's question even hits the LLM, we sanitize it.
- PII Redaction: Use a regex script to detect credit card numbers or SSNs and replace them with
[REDACTED]. - Topic Restriction: If the user asks the Banking Bot "Write a poem about Trump," the Guardrail detects the intent is "Politics" (not "Banking") and returns a hard-coded rejection: "I can only discuss your account."
B. Output Guardrails (The Fact-Checker)
This is where we catch hallucinations. Before the AI's answer is shown to the user, it runs through a verification loop.
- Self-Correction: We ask a second, smaller AI: "Does this answer contradict the provided context?" If Yes, we regenerate the answer.
- Format Enforcement: If the output must be JSON, we run a parser check. If the JSON is broken, the user never sees it; the system retries automatically.
3. Evaluation: LLM-as-a-Judge
How do you know if your Guardrails work? You cannot manually read 10,000 chat logs every day.
You need Automated Evals.
We use a technique called "LLM-as-a-Judge."
- Create a "Golden Dataset": 100 questions with known, perfect answers (Ground Truth).
- Run the System: Feed these questions to your AI.
- The Judge: Use a massive model (like GPT-4) to grade your AI's answers against the Golden Answers.
- "Did the answer mention the refund policy? Yes/No."
- "Was the tone polite? Yes/No."
If your "Hallucination Score" usually sits at 2%, and suddenly spikes to 8% after a deployment, you stop the release. This brings DevOps discipline to AI.
4. The Human Circuit Breaker
There are some risks that software cannot catch.
For "High Consequence" actions (approving a loan, diagnosing a disease, sending a legal threat), you must implement a Human-in-the-Loop (HITL).
The Design Pattern:
- Low Risk (Reset Password): AI handles 100%.
- Medium Risk (Refund < $50): AI handles, with post-hoc audit.
- High Risk (Refund > $500): AI generates the draft approval and summarizes the evidence. A Human Agent must click "Approve."
The AI becomes the Co-pilot, not the Autopilot.
This is the ultimate defense in court. "The AI didn't approve the refund; the Agent did (based on AI advice)."
Summary
We are moving from the era of "AI Magic" to the era of "AI Engineering."
Magic is unpredictable. Engineering is constrained.
- Don't trust the model. (It is a probabilistic token generator).
- Trust the pipeline. (Input filters, RAG context, Output verification).
- Measure the drift. (Automated Evals).
If you cannot measure how often your AI lies, you are not ready to deploy it.
No spam, no sharing to third party. Only you and me.





Member discussion